CCFtab
目录
1.常用注意要点
2.常用stl详解以及使用方式简述
- 2.1 map
- 2.2 unordered_map、multimap
- 2.3 vector
- 2.4 queue
- 2.5 stack
- 2.6 set
3.常用函数原型以及解释(随时添加)
#includ<ctype.h>
#include<algorithm>
#include<string>
4.运用文件读写加快测试速度的代码
常用注意要点
1.#include
万能头文件,包含了所有的已知常用库
2.ios::sync_with_stdio(false);
为了防止因为cin以及cout产生超时,将cin以及cout的缓冲区置为false
3.cin.tie(0);
接触cin与cout的绑定,加快执行效率
常用stl详解以及使用方式
stl中很常用的一个东西就是迭代器iterator,但是注意,iterator相当于是指向节点的指针,所以在整个stl发生改变或者删除时会出现迭代器产生空指针的情况,所以要牢记一点:不要用过期的iterator!!!
如果希望将一个结构体作为几种stl的键值时需要将struct中的某一个值作为键值对<进行重载,具体方法如下:
1 | struct Info |
1.map
map是键-值对的组合,有以下的一些定义的方法:
map<k, v> m;map<k, v> m(m2);map<k, v> m(b, e);
上述第一种方法定义了一个名为m的空的map对象;第二种方法创建了m2的副本m;第三种方法创建了map对象m,并且存储迭代器b和e范围内的所有元素的副本。
map的value_type是存储元素的键以及值的pair类型,键为const。
插入
insert函数的插入方法主要有如下:
m.insert(e)m.insert(beg, end)m.insert(iter, e)
上述的e一个value_type类型的值。beg和end标记的是迭代器的开始和结束。
两种插入方法如下面的例子所示:
1 |
|
Map中可以利用结构体作为key值,但是要对小于号进行符号重载
例如:
1 | struct Point |
查找
上述采用下标的方法读取map中元素时,若map中不存在该元素,则会在map容器中插入一个新的元素。
因此,若只是查找该元素是否存在,可以使用函数count(k),该函数返回的是k出现的次数;若是想取得key对应的值,可以使用函数find(k),该函数返回的是指向该元素的迭代器。
1 | map<int, int>::iterator it_find; |
find一定会使用迭代器,所以要学会对迭代器进行初始化
map<int, int>::iterator it_find;
删除
从map中删除元素的函数是erase(),该函数有如下的三种形式:
m.erase(k)m.erase(p)m.erase(b, e)
第一种方法删除的是m中键为k的元素,返回的是删除的元素的个数;第二种方法删除的是迭代器p指向的元素,返回的是void;第三种方法删除的是迭代器b和迭代器e范围内的元素,返回void。
1 | map<int, int> mp; |
map常用函数
1 | map<char,int> mymap; |
2.unordered_map
map内部实现的是一个黑红树,具有自动排序功能,因此map所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。
在有对于顺序要求的问题中,map会更高效,但是map的每个节点占用空间更大。
而对于查找问题来说,unordered_map会更加高效,因为哈希表查找速度非常快,但是哈希表建立比较消耗时间。
其操作与map相同。
multimap
mutimap容器一样保存的是有序的键值对,但是与map不同的是他可以保存重复的元素,multimap 也同样是一颗红黑树,会将插入的键值自动排序
3.vector
vector是向量类型,可以容纳许多类型的数据,因此也被称为容器,
vector初始化:
方式1.
1 | //定义具有10个整型元素的向量(尖括号为元素类型名,它可以是任何合法的数据类型),不具有初值,其值不确定 |
方式2.
1 | //定义具有10个整型元素的向量,且给出的每个元素初值为1 |
方式3.
1 | //用向量b给向量a赋值,a的值完全等价于b的值 |
方式4.
1 | //将向量b中从0-2(共三个)的元素赋值给a,a的类型为int型 |
方式5.
1 | //从数组中获得初值 |
常用内置函数
1 |
|
注意事项
通过下标访问时只能访问存在的元素,
几个常用的算法
1 |
|
4.queue
只能访问queue
queue的基本操作如下图:
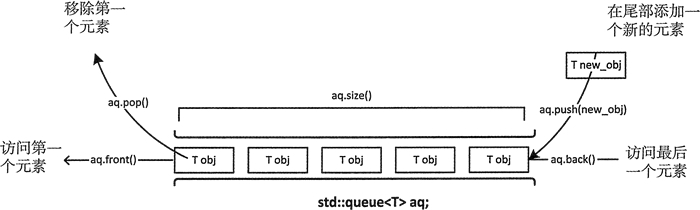
queue 和 stack 有一些成员函数相似,但在一些情况下,工作方式有些不同:
1 | queue<string>q; |
5.stack
1 | stack<int>s1; |
6.set
set容器是用来存储同一数据类型的数据类型,并能从一个数据集合取出数据,在set中每个元素的值都唯一,系统能根据元素的值自动排序,应注意set中的每个值都不能直接被改变。与map相同,set的内部同样实现的是黑红树。
常用方法
1 | //将key_value插入到set中 ,返回值是pair<set<int>::iterator,bool>,bool标志着插入是否成功,而iterator代表插入的位置,若key_value已经在set中,则iterator表示的key_value在set中的位置。 |
常用函数原型以及解释
以下函数以及头文件均包含在bits/stdc++.h中,无需特殊声明。
#include<ctype.h>
这几个都是返回非0表示正确,返回0表示错误
1.isalnum(int c);
用来判断一个字符是否是字母或者十进制数字。其中c表示要检测的字符,(被转化为int类型,可以直接输入char)也可以是EOF
2.islower(int c);
用来检测一个字符是不是小写字母,其中c表示要检测的字符,(被转化为int类型,可以直接输入char)也可以是EOF
3.isalpha(int c);
用来检测一个字符是不是字母,其中c表示要检测的字符,(被转化为int类型,可以直接输入char)也可以是EOF
4.isdigit(int c);
用来检测一个字符是不是数字,其中c表示要检测的字符,(被转化为int类型,可以直接输入char)也可以是EOF
5.isblank(int c);
用来检测一个字符是不是空白符,其中c表示要检测的字符,这个函数仅检测空格‘’,水平制表符‘/t’,如果想检测更多的话需要用函数isspace();
6.iscntrl(int c);
iscntrl() 函数用来检测一个字符是否是控制字符(Control Character)。控制字符的范围是0x00 (NUL) ~ 0x1f (US),再加上一个0x7f (DEL)字符。
7.isgraph(int c);
isgraph() 函数用来检测一个字符是否是图形字符。
8.ispunct(int c);
ispunct() 函数用来检测一个字符是否是标点符号。
9.isupper ( int c );
isupper() 函数用来检测一个字符是否是大写字母。
10.isxdigit ( int c );
isxdigit() 用来检测一个字符是否是十六进制数字。
11.tolower ( int c );
tolower() 函数用来将大写字母转换为小写字母。
12.toupper ( int c );
toupper() 函数用来将小写字母转换为大写字母。
#include<algorithm>
1.reverse(it,it2)
将数组指针在[it,it2)之间的元素或容器的迭代器在[it,it2)范围内的元素进行反转。string也可以。
1 | int a[10]= {10, 11, 12, 13, 14, 15}; |
2.sort(a,a+k,cmp)
sort(首元素地址(必填), 尾元素地址的下一个地址(必填), 比较函数(非必填));不填写时默认为递增序列。
1 | int a[6] = {9, 4, 2, 5, 6, -1}; |
#include<string>
1.void *memchr(const void *str, int c, size_t n)
在参数str指向的字符串的前n个字节中搜索第一次出现字符c(无符号字符)的位置
1 |
|
2.int memcmp(const void*str1,const void*str2,size_t n);
将str1和str2的前n个字节进行比较
字符串相等返回0,字符串前大于后返回1否则返回0
3.void *memcpy(void *dest, const void *src, size_t n)
从 src 复制 n 个字符到 dest。
4.void *memmove(void *dest, const void *src, size_t n)
另一个用于从 src 复制 n 个字符到 dest 的函数。
5.void *memset(void *str, int c, size_t n)
复制字符 c(一个无符号字符)到参数 str 所指向的字符串的前 n 个字符。
6.char *strcat(char *dest, const char *src)
把 src 所指向的字符串追加到 dest 所指向的字符串的结尾。
该函数返回一个指向最终的目标字符串 dest 的指针。
7.char *strncat(char *dest, const char *src, size_t n)
把 src 所指向的字符串追加到 dest 所指向的字符串的结尾,直到 n 字符长度为止。
8.char *strchr(const char *str, int c)
在参数 str 所指向的字符串中搜索第一次出现字符 c(一个无符号字符)的位置。
9.int strcmp(const char *str1, const char *str2)
把 str1 所指向的字符串和 str2 所指向的字符串进行比较。
该函数返回值如下:
- 如果返回值小于 0,则表示 str1 小于 str2。
- 如果返回值大于 0,则表示 str1 大于 str2。
- 如果返回值等于 0,则表示 str1 等于 str2。
10.int strncmp(const char *str1, const char *str2, size_t n)
把 str1 和 str2 进行比较,最多比较前 n 个字节。
11.int strcoll(const char *str1, const char *str2)
把 str1 和 str2 进行比较,结果取决于 LC_COLLATE 的位置设置。
12.char *strcpy(char *dest, const char *src)
把 src 所指向的字符串复制到 dest。
13.char *strncpy(char *dest, const char *src, size_t n)
把 src 所指向的字符串复制到 dest,最多复制 n 个字符。
14.size_t strcspn(const char *str1, const char *str2)
检索字符串 str1 开头连续有几个字符都不含字符串 str2 中的字符。
该函数返回 str1 开头连续都不含字符串 str2 中字符的字符数。
以匹配到第一个字符为准。
15.char *strerror(int errnum)
从内部数组中搜索错误号 errnum,并返回一个指向错误消息字符串的指针。strerror生成的错误字符串取决于开发平台和编译器。
16.size_t strlen(const char *str)
计算字符串 str 的长度,直到空结束字符,但不包括空结束字符。
17.char *strpbrk(const char *str1, const char *str2)
检索字符串 str1 中第一个匹配字符串 str2 中字符的字符,不包含空结束字符。
该函数返回 str1 中第一个匹配字符串 str2 中字符的字符数,如果未找到字符则返回 NULL。
1 | const char str1[] = "abcde2fghi3jk4l"; |
18.char *strrchr(const char *str, int c)
在参数 str 所指向的字符串中搜索最后一次出现字符 c(一个无符号字符)的位置。
19.size_t strspn(const char *str1, const char *str2)
检索字符串 str1 中第一个不在字符串 str2 中出现的字符下标。
20.char *strstr(const char *haystack, const char *needle)
在字符串 haystack 中查找第一次出现字符串 needle(不包含空结束字符)的位置。
21.char *strtok(char *str, const char *delim)
分解字符串 str 为一组字符串,delim 为分隔符。
22.size_t strxfrm(char *dest, const char *src, size_t n)
根据程序当前的区域选项中的 LC_COLLATE 来转换字符串 src 的前 n 个字符,并把它们放置在字符串 dest 中。
运用文件读写加快测试速度的代码
1 |
|
在创建.cpp文件的地方创建in.txt文件和out.txt文件